切片与非切片
- 在单服务器,或一主多从服务器模式,就是非切片模式。
- 切片模式是多主多从。切片使用非一致性哈希算法,在多主服务器上散列 key。
配置、持久化、复制
Redis的配置主要放置在 redis.conf,可以通过修改配置文件实现 Redis 许多特性,比如复制,持久化,集群等。
redis.conf 部分配置详解
# 启动 redis,显示加载配置 redis.conf
# ./redis-server /path/to/redis.conf
# 停止 redis
# redis-cli -h IP -p PORT shutdown
# 可以包含一个或多个其他配置文件,如果多个 redis 服务器存在标准配置模板,但是每隔 redis 服务器可能有个性化的配置
# include /path/to/local.conf
# include /path/to/other.conf
# 对于一个redis服务器来说可以有一个或者多个网卡。比如服务器上有两个网卡:bind 192.168.1.100 192.168.1.101,如果 bind 192.168.1.100,则只有该网卡地址接受外部请求,如果不绑定,则两个网卡都接受请求
# bind 192.168.1.100 192.168.1.101
# bind 127.0.0.1 ::1
# 监听端口号,默认为6379,如果为0监听任连接
port 6379
# TCP 连接中已完成队列的长度
tcp-backlog 511
#客户端和 Redis 服务端的连接超时时间,默认为0表示永不超时
timeout 0
# 服务端周期性时间(单位秒)验证客户端是否处在健康状态,避免服务端一直阻塞
tcp-keepalive 300
# Redis 以后台守护进程形式启动
daemonize yes
# 配置 PID 文件路径,当redis以守护进程启动时,它会把PID默认写到 /var/redis/run/redis_6379.pid文件里面
pidfile "/var/run/redis_6379.pid"
#Redis日志级别:debug,verbose,notice,warning,级别一次递增
loglevel notice
#日志文件路径及名称
logfile ""
持久化
为了能够重用 Redis 数据,或者防止系统故障,我们需要将 Redis 中的数据写入到磁盘空间中,即持久化。
Redis提供了两种不同的持久化方法可以将数据存储在磁盘中,一种叫快照(RDB),另一种叫只追加文件(AOF)。
RDB 方式
Redis 通过创建快照的方式获取某一时刻 Redis 中所有数据的副本。用户可以针对该快照进行各种操作,比如:将快照复制到其他服务器从而完成 Redis 的主从复制,或者将快照留在原地,服务器重启的时候重用数据。
根据配置文件,可以手动设置Redis快照名及路径:
# RDB文件名
dbfilename "dump.rdb"
# RDB文件和AOF文件路径
dir "/usr/local/var/db/redis"
Redis创建快照主要有以下几种方式:
(1) 客户端直接通过命令BGSAVE或者SAVE来创建一个快照
-
BGSAVE是通过redis调用fork来创建一个子进程,然后子进程负责将快照写入磁盘,而父进程仍然继续处理命令。
-
SAVE是在没有足够的内存空间去执行BGSAVE或者无所谓等待的时候。执行SAVE命令过程中,redis不在响应任何其他命令。
(2) 在 redis.conf 中设置 save 配置选项(应用开发中比较常用)
# 在规定的时间内,Redis 发生写操作的次数的条件,会触发 BGSAVE 命令。
# save <seconds> <changes>
# 当用户设置了多个 save 的选项配置,只要其中任一条满足,Redis 都会触发一次 BGSAVE 操作,比如:900秒之内至少一次写操作、300秒之内至少发生10次写操作、60秒之内发生至少10000次写操作都会触发发生快照操作
save 900 1
save 300 10
save 60 10000
(3) 当 Redis 通过 shutdown 命令关闭服务器请求时,会执行 SAVE 命令创建一个快照,如果使用 kill -9 PID 将不会创建快照。
(4) 主从同步,这个将在下面一小节讲解。
(5) 注意:
- 在只使用快照持久化来报错数据时,如果系统崩溃或者强杀,用户将会丢失最近一次生成快照之后更改的所有数据。因此如果应用程序对于两次快照间丢失的数据可接受,利用快照就是一个很好的方式,但是往往一些系统对于丢失几分钟的数据都不可接受,比如高频的电子商务系统。
- 此外,如果 Redis 存储的数据量长达数十 G 的时候,每执行一次快照需要花费大量时间,严重影响到服务器的性能。
因此,针对上述的问题,可以使用 AOF 方式来持久化数据。
AOF 方式
在执行写命令时,AOF 持久化会将执行的写命令也写到 AOF 文件的末尾,以此来记录数据的变化。换句话说,将 AOF 文件中包含的内容重新执行一遍,就可以回复 AOF 文件所记录的数据集。
在 Redis.conf 配置中设置如下:
# redis 默认关闭 AOF 机制,可以将 no 改成 yes 实现 AOF 持久化
appendonly no
# AOF 文件
appendfilename "appendonly.aof"
# AOF 持久化同步频率,always 表示每个 Redis 写命令都要同步 fsync 写入到磁盘中,但是这种方式会严重降低 redis 的速度;everysec 表示每秒执行一次同步 fsync,显示的将多个写命令同步到磁盘中;no 表示让操作系统来决定应该何时进行同步 fsync,Linux 系统往往可能30秒才会执行一次
# appendfsync always
appendfsync everysec
# appendfsync no
# 在日志进行 BGREWRITEAOF 时,如果设置为 yes 表示新写操作不进行同步 fsync,只是暂存在缓冲区里,避免造成磁盘 IO 操作冲突,等重写完成后在写入。redis 中默认为 no
no-appendfsync-on-rewrite no
# 当前 AOF 文件大小是上次日志重写时的 AOF 文件大小两倍时,发生 BGREWRITEAOF操作。
auto-aof-rewrite-percentage 100
# 当前 AOF 文件执行 BGREWRITEAOF 命令的最小值,避免刚开始启动 Reids时由于文件尺寸较小导致频繁的 BGREWRITEAOF。
auto-aof-rewrite-min-size 64mb
# Redis 再恢复时,忽略最后一条可能存在问题的指令(因为最后一条指令可能存在问题,比如写一半时突然断电了)
aof-load-truncated yes
# Redis4.0 新增 RDB-AOF 混合持久化格式,在开启了这个功能之后,AOF 重写产生的文件将同时包含 RDB 格式的内容和 AOF 格式的内容,其中 RDB 格式的内容用于记录已有的数据,而 AOF 格式的内存则用于记录最近发生了变化的数据,这样Redis就可以同时兼有 RDB 持久化和 AOF 持久化的优点(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据)。
aof-use-rdb-preamble no
RDB 与 AOF 同时开启,默认先加载 AOF 的配置文件,因此需要根据具体情况使用,4.0+的可以使用 RDB-AOF 混合持久化格式。
复制
本部分只介绍主从同步的简单实现,并利用哨兵机制实现高可用,不介绍集群 Cluster 无中心的方式。
Redis 主从复制
在 Redis 中实现主从复制比较简单,只需要修改 slave 服务器的 redis.conf 中的 slaveof。下面利用一个具体的实例展示主从同步。
主从复制示例
环境如下: MacOS,Redis 版本4.0.2
master 服务器:127.0.0.1 : 6379
slave 服务器:127.0.0.1 : 6399
配置 slave 服务器:
# 设置 master 服务器 IP 和端口
slaveof 127.0.0.1 6379
# slave 是否只读,从服务器负责读操作,主服务器负责写操作,从而实现读写分离
slave-read-only yes
分别按照顺序启动 mater (redis-server redis.conf)和 slave(redis-server redis2.conf)
在 master 中添加元素,在 slave 服务器中可以获得元素。
主从复制如何交互
下面来研究下 slave 服务器和 master 服务器间是如何建立起主从同步机制的。
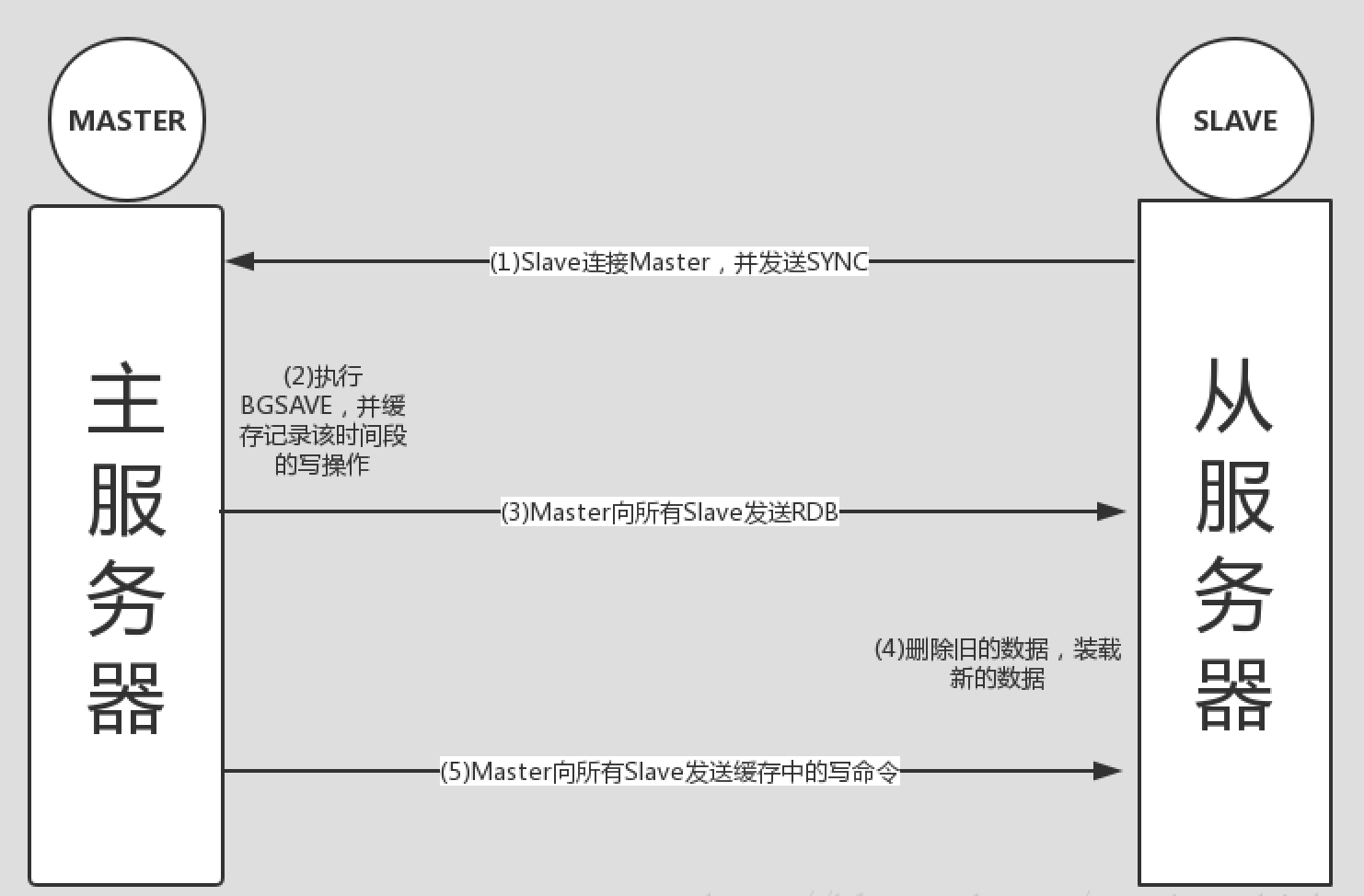
- Slave 服务启动,主动连接 Master,并发送 SYNC 命令,请求初始化同步
- Master 收到 SYNC 后,执行 BGSAVE 命令生成 RDB 文件,并缓存该时间段内的写命令
- Master 完成 RDB 文件后,将其发送给所有 Slave 服务器
- Slave 服务器接收到 RDB 文件后,删除内存中旧的缓存数据,并装载 RDB 文件
- Master 在发送完 RDB 后,即刻向所有 Slave 服务器发送缓存中的写命令
- 至此初始化完成,后续进行增量同步
上述主从复制模式链是非常脆弱的,一旦 Master 服务器发生宕机,会导致无法向 redis 中读取或者写入数据,高可用性极差。
高可用性集群
上述主从复制机制,简单地实现了 Redis 高可用。然而,Master服务器宕机,会导致整个 Redis 瘫痪,这种方式的高可用性较低。正常会采用多台 Redis 服务器构成一个集群,即使某台,或者某几台 Redis 宕机,Redis 集群仍能正常运行,从而提高其可用性。
在 Redis 中,主要存在两种方式实现 Redis 集群机制:
- Redis Sentinel 集群机制: 在 Redis2.X 版本,往往都是通过这种方式实现 Redis 的高可用。redis-sentinel 是在 master-slave 机制上加入监控机制哨兵 Sentinel 实现的。
- Redis Cluster 集群机制: 在 Redis3.0 版本后推出了 redis-cluster 集群机制。redis-cluster 集群中各个节点之间是对等的,即 master-master 模式。
注意:Redis Sentinel 集群是解决 HA 问题的(主从同步),Redis Cluster 集群是解决 sharding 问题的(分区),两种不重复,可以混合使用。
下面详细说明这两种集群,并给出具体的演示示例。
Redis Sentinel 集群机制
Redis-Sentinel 是在 master-slave 机制上加入监控机制哨兵 Sentinel 实现的。Sentinel 主要功能就是为 Redis Master-Slave 集群提供:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
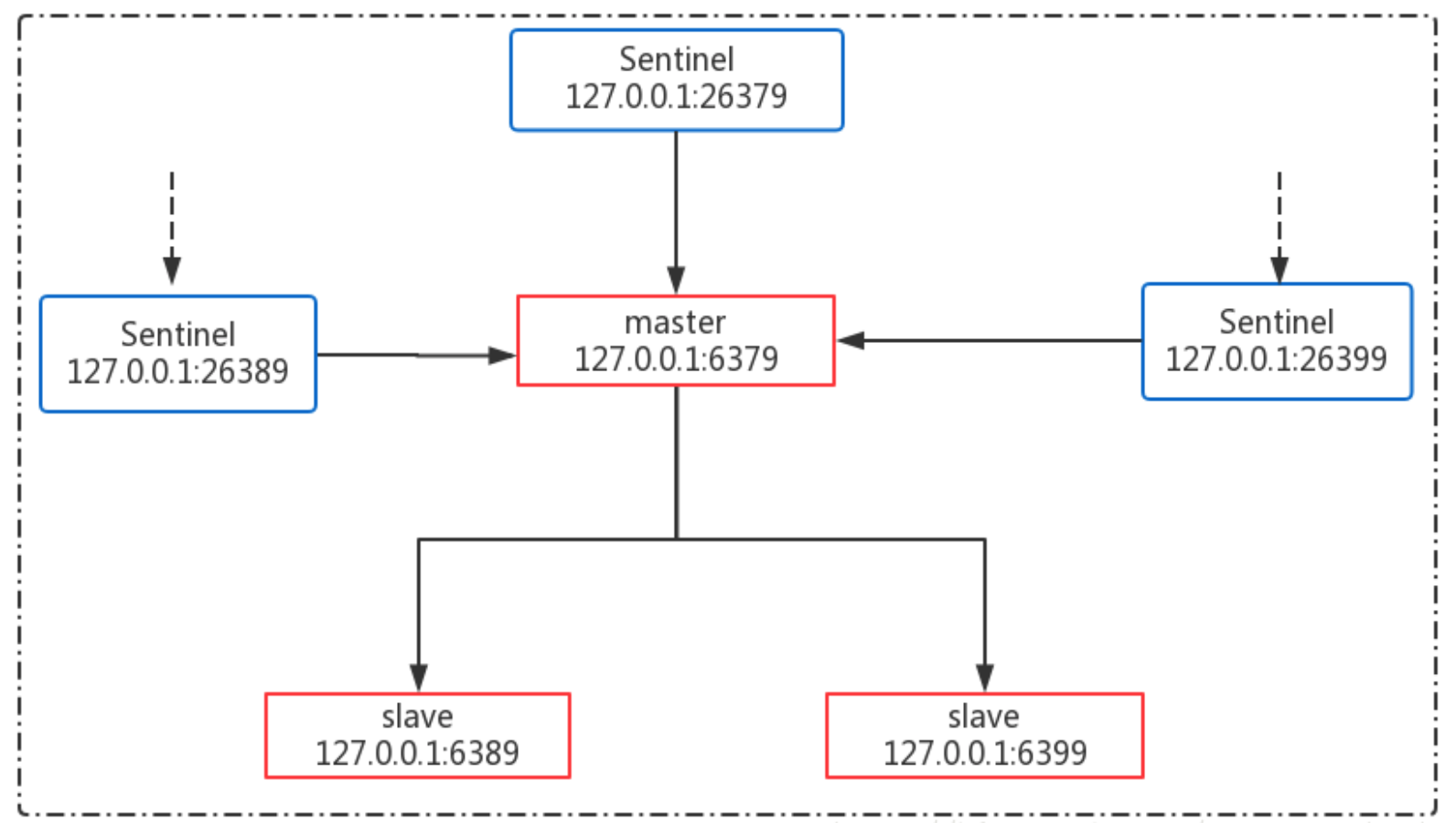
在 Sentinel 集群中,一个最小的 Master-Slave 单元包含一个 master 和一个 slave 服务器。当 master 失效后,sentinel 自动将 slave 提升为 master,从而可以减少管理员的人工切换 slave 的操作过程。
Redis-Sentinel 集群架构图
各个机器配置
部署在本地机器上,保证各个端口号不一样,具体配置如下
Redis 服务器:
-
master: 127.0.0.1:6379
- slave01: 127.0.0.1:6389
- slave02: 127.0.0.1:6399
Sentinel 服务器
- sentinel01: 127.0.0.1:26379
- sentinel02: 127.0.0.1:26389
- sentinel03: 127.0.0.1:26399
redis.conf 和 sentinel.conf 配置
redis.conf
master 特殊配置如下:
# 后台线程启动
daemonize yes
# 监听端口号
port 6379
# 访问验证密码
requirepass "123456"
slave 特殊配置如下:
# 后台线程启动
daemonize yes
# 监听端口号,如果为 slave02,端口号为6399
port 6389
# 主节点访问密码
masterauth "123456"
# 访问验证密码
requirepass "123456"
# 主节点服务器 IP 和端口号
slaveof 127.0.0.1 6379
sentinel.conf
# 后台线程启动
daemonize yes
# 监听端口号,如果为 sentinel02,则端口号为26389,如果为 sentinel01,则端口号为26399
port 26379
# 1表示在 sentinel 集群中只要有两个节点检测到 redis 主节点出故障就进行切换
sentinel monitor mymaster 127.0.0.1 6379 1
# master 节点密码验证
sentinel auth-pass mymaster 123456
# 如果3秒内 mymaster 无响应,则认为 mymaster 宕机了
sentinel down-after-milliseconds mymaster 3000
# 选项指定了在执行故障转移时,最多可以有多少个从服务器同时对新的主服务器进行同步,这个数字越小,完成故障转移所需的时间就越长
sentinel parallel-syncs mymaster 1
# 如果10秒后,mysater 仍没活过来,则启动 failover
sentinel failover-timeout mymaster 10000
注意:
- 如果上述涉及的所有配置均放置在同一目录下,需保证各配置名称不同;
- 在配置中,不同实例的日志输出、快照文件要求名称不能一样,具体可自行配置;
- 一定要保证”sentinel myid”不相同,否则无法进行故障转移。
启动集群及启动后结果详情展示
各Redis节点启动:
redis-server redis_****.conf
各Sentinel节点启动:
redis-sentinel sentinel_****.conf
Redis Master节点详情展示:
这里写图片描述 Redis Slave节点效果截图展示 这里写图片描述 各个Sentinel节点详情展示 这里写图片描述 1.5 高可用性场景测试
Master宕机 这里写图片描述 sentinel使用failover机制重新选举出master Master恢复 这里写图片描述 master节点恢复后,由Master变成slave Slave宕机 这里写图片描述 哨兵发现6399已经宕机,等待6399的恢复(主观下线) Slave重启6399节点 这里写图片描述 如果想详细了解sentinel机制的话,可以参考博客: http://shift-alt-ctrl.iteye.com/blog/1884370
Redis Cluster 集群机制
Redis-cluster 介绍
Redis-cluster 是一种服务器 Sharding 技术,Redis3.0 以后版本正式提供支持。
Redis-cluster 没有使用一致性 hash,而是引入了哈希槽的概念。Redis-cluster 中有16384个哈希槽,每个 key 通过 CRC16 校验后对16384取模来决定放置哪个槽。Cluster 中的每个节点负责一部分 hash 槽(hash slot),比如集群中存在三个节点,则可能存在的一种分配如下:
-
节点A包含0到5500号哈希槽;
- 节点B包含5501到11000号哈希槽;
- 节点C包含11001 到 16384号哈希槽。
这种集群架构很容易扩展,如果扩充一个节点 D,只需要将 A、B、C 节点中的部分槽放置在 D 上;如果想移除节点 A,只需要将 A 的 slot 转移到 B 和 C 节点上。由于将哈希槽从一个节点移动到另一个节点不需要停止服务,只需要通过命令直接再分配,因而上述拓展不会造成集群不可用。目前这种方式还是一种半自动的方式,需要人工介入。
Redis-Cluster主从复制
在 Redis-Cluster 中,如果某个节点宕机或者处在不可用状态时,那它负责的 Hash槽也将失效,导致整个集群不可用。因而为了提供高可用性,正常会将每个节点配置成主从式结构,即一个 master 节点,挂在多个 slave 节点。如果 Master 节点失效时,集群便会选取一个 slave 节点作为 master,继续提供服务,从而不会导致整个集群不可用。
Redis-Cluster集群模拟
2.3.1 Redis-Cluster集群准备
集群部署图 这里写图片描述 集群由三个节点组成,每个节点均为主从式架构。因而共需要创建6个Redis实例,分配如下:
Redis01:127.0.0.1:7000 Redis02:127.0.0.1:7001 Redis03:127.0.0.1:7002 Redis04:127.0.0.1:7003 Redis05:127.0.0.1:7004 Redis06:127.0.0.1:7005 对于每个实例的redis_700*.conf配置如下:
监听端口号
port 700*
开启集群
cluster-enabled yes
修改集群加载配置文件,不需要手动创建,启动后默认生成,并且需要时自动更新
cluster-config-file /Users/guweiyu/develop/redis/redis-cluster/workpid/nodes-7000.conf
集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障
cluster-node-timeout 15000
默认为“no”,表示部分Key所在的节点不可用时,集群仍然为可达节点提供服务;如果为“yes”,表示部分key所在的节点不可用时,则整个集群停止服务。注意:实际使用中要修改为”yes”
cluster-require-full-coverage no 1 2 3 4 5 6 7 8 9 10 11 安装ruby,如果为Mac OS系统,直接执行即可:
brew install ruby 1 2.3.2 集群启动
启动所有Redis实例,可以编写一个启动和停止所有redis实例的脚本(start.sh,stop.sh)
redis-server redis_7000.conf redis-server redis_7001.conf redis-server redis_7002.conf redis-server redis_7003.conf redis-server redis_7004.conf redis-server redis_7005.conf
ps -ef | grep redis-server echo “redis 7000-7005全部启动完成” 1 2 3 4 5 6 7 8 9 redis-cli -p 7000 shutdown redis-cli -p 7001 shutdown redis-cli -p 7002 shutdown redis-cli -p 7003 shutdown redis-cli -p 7004 shutdown redis-cli -p 7005 shutdown
ps -ef | grep redis-server echo “redis-server 7000-7005节点已全部停止” 1 2 3 4 5 6 7 8 9 创建redis-cluster Redis中创建集群是通过redis-trib.rb命令实现的,redis-trib.rb位于Redis源码的src目录下,可将其直接拷贝到当前目录下。
运行命令
./redis-trib.rb create –replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 1 如果出现如下错误:
/System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/lib/ruby/2.3.0/rubygems/core_ext/kernel_require.rb:55:in require': cannot load such file -- redis (LoadError)
from /System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/lib/ruby/2.3.0/rubygems/core_ext/kernel_require.rb:55:in require’
from ./redis-trib.rb:25:in `<main>’
1
2
3
这是由于没有安装redis的第三方接口导致的。因此需要给Ruby安装client包,如下(必须加上sudo执行,否则会执行失败):
sudo gem install redis 1 再执行创建集群命令,结果如下:
Creating cluster Performing hash slots allocation on 6 nodes… Using 3 masters: 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 Adding replica 127.0.0.1:7004 to 127.0.0.1:7000 Adding replica 127.0.0.1:7005 to 127.0.0.1:7001 Adding replica 127.0.0.1:7003 to 127.0.0.1:7002 Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: aab0162a039d2f224322afe6caf2e153230f2d82 127.0.0.1:7000 slots:0-5460 (5461 slots) master M: 058204226f52757925a606b9697a8e39756bfdff 127.0.0.1:7001 slots:5461-10922 (5462 slots) master M: 857075aef280cf35cd369ebc30738cd31c05e479 127.0.0.1:7002 slots:10923-16383 (5461 slots) master S: 7dac141fa9510315905f505be52bba0208c391ab 127.0.0.1:7003 replicates aab0162a039d2f224322afe6caf2e153230f2d82 S: 65a2bc432e5930e97f0fd172eb838af9f07229b6 127.0.0.1:7004 replicates 058204226f52757925a606b9697a8e39756bfdff S: 3d2a665d2e2eb28acb0a187c1a0b4bbce9ce87d2 127.0.0.1:7005 replicates 857075aef280cf35cd369ebc30738cd31c05e479 Can I set the above configuration? (type ‘yes’ to accept): yes Nodes configuration updated Assign a different config epoch to each node Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join… Performing Cluster Check (using node 127.0.0.1:7000) M: aab0162a039d2f224322afe6caf2e153230f2d82 127.0.0.1:7000 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 3d2a665d2e2eb28acb0a187c1a0b4bbce9ce87d2 127.0.0.1:7005 slots: (0 slots) slave replicates 857075aef280cf35cd369ebc30738cd31c05e479 S: 65a2bc432e5930e97f0fd172eb838af9f07229b6 127.0.0.1:7004 slots: (0 slots) slave replicates 058204226f52757925a606b9697a8e39756bfdff S: 7dac141fa9510315905f505be52bba0208c391ab 127.0.0.1:7003 slots: (0 slots) slave replicates aab0162a039d2f224322afe6caf2e153230f2d82 M: 857075aef280cf35cd369ebc30738cd31c05e479 127.0.0.1:7002 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: 058204226f52757925a606b9697a8e39756bfdff 127.0.0.1:7001 slots:5461-10922 (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. Check for open slots… Check slots coverage… [OK] All 16384 slots covered. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 创建成功,16384个Hash槽分配完成,所有节点(Master和slave节点)均已加入到集群中。三个Master节点分配的Hash槽及从节点如下:
Master01:127.0.0.1:7000
M: aab0162a039d2f224322afe6caf2e153230f2d82 slots:0-5460 (5461 slots) master 127.0.0.1:7004 to 127.0.0.1:7000 1 2 3 Master02:127.0.0.1:7001
M: 058204226f52757925a606b9697a8e39756bfdff slots:5461-10922 (5462 slots) master 127.0.0.1:7005 to 127.0.0.1:7001 1 2 3 Master03:127.0.0.1:7002
M: 857075aef280cf35cd369ebc30738cd31c05e479 slots:10923-16383 (5461 slots) master 127.0.0.1:7003 to 127.0.0.1:7002 1 2 3 2.3.3 集群测试
测试集群存取值 客户端命令redis-cli连接集群需要带上”-c”, 比如redis-cli -c -p 端口号
127.0.0.1:7000> set test1 guweiyu OK 127.0.0.1:7000> set name guweiyu -> Redirected to slot [5798] located at 127.0.0.1:7001 OK 127.0.0.1:7001> get name “guweiyu” 127.0.0.1:7001> get test1 -> Redirected to slot [4768] located at 127.0.0.1:7000 “guweiyu” 127.0.0.1:7000> 1 2 3 4 5 6 7 8 9 10 11 测试发现”set test1 guweiyu”,直接返回OK,说明该值就是存储在7000上,执行“set name guweiyu”发生了Redirected到7001上,获取的时候,同样出现上述情况。这个是Redis Cluster去中心特性,访问集群中的任一节点,均可直接操作集群。
主节点宕机测试
从节点宕机